“ملاحظة: قد يجد غير المختص في هذا المقال طلاسم .. لا أنصح بالقراءة لأصحاب القلوب الضعيفة..!”
في مدونة اليوم سأجيب على استفسار وردني في تويتر من أحد الأصدقاء الأعزاء:
يقول في سؤاله:”في مدونتك السابقة دونت حول التعاطي مع البيانات وتعدينها واستخراج الميزات او الخصائص منها feature extraction. واختيار أفضلها. سؤالي اليك ..هل استخراج الخصائص واختيارها أمر عشوائي؟ ولعلك تفيدنا بشكل مفصل خصوصا أن رسالتك الدكتوراه في هذا المجال.”
الجواب: أبدأ بمقدمة بسيطة عن الإختيار Selelction والاستخراج Extraction..
استخراج الخصائص Feature Extraction FE و اختيار الخصائص Feature Selection FS أمران مختلفان عن بعضهما كثيراً، وإن كان يحدث من بعض المختصين خلط كبير بينهم. فاستخراج الخصائص FE هو أن تأتي على فضاء الخصائص Feature Space وتحولها لفضاء آخر غالبا يكون عدد الأبعاد فيه أقل.وهنا يتم تغيير للخصائص عن أصلها كليا. فمثلا لو أن لديك بيانات حيوية لعدد خمسة آلاف جين DNA. وأردت أن تقوم بتقليل عدد الجينات لتعطي نتائج أفضل، وقمت بعمل FE عليها فإن خصائص البيانات الناتجة عندك لن تكون جينات.
وعلى العكس تماماً فإن اختيار الخصائص FS لايغير من طبيعة الخصائص. وكل مانقوم به هو أن نختار الخصائص التي تكون أكثر مناسبة للمشكلة التي لدينا. فلو أننا في مثال الجينات نحاول أن نستخرج الجينات ذات العلاقة بمرض ما، فإننا نقوم باختيار الخصائص ذات العلاقة الأكبر بالمرض.
عودة على السؤال، هل يتم ذلك عشوائياً؟ لعلك تقصد الإختيار..بالتأكيد لا. لكن لكن خوارزمية طريقة في الإختيار. فمنها مايقوم باختيار الخصائص الأكثر قدرة على التصنيف Classification Accuracy، ومنها من يتم إختياره بناء على كفاءة التعلم Learning Performance حسب الهدف من التعلم. ومنها مايتم اختياره بناء على الارتباط بين الخاصية ونوع البيانات Correlation ومنها مايقوم فقط بحذف الخصائص المتكررة أو المتشابهه كثيرا Redundancy… الخ.
وفي مثالنا في المدونة السابقة كانت طريقة الاختيار حسب القدرة على التصنيف. انظر الشكل الأول أدناه، لترى الخصائص التي تم اختياره (اختيارها وليس استخراجها) من المئة صورة. لاحظ أنها عبارة عن بيكسيلز Pixcels .. ولم تتغير طبيعتها .. ولاحظ أن الخوارزمية التي استخدمناها ReliefF وجدت أن البيكسلز التي في منطقة العينين والخد من جهة اليمين قادرة على تمييز الصور بشكل دقيق لحد كبير.
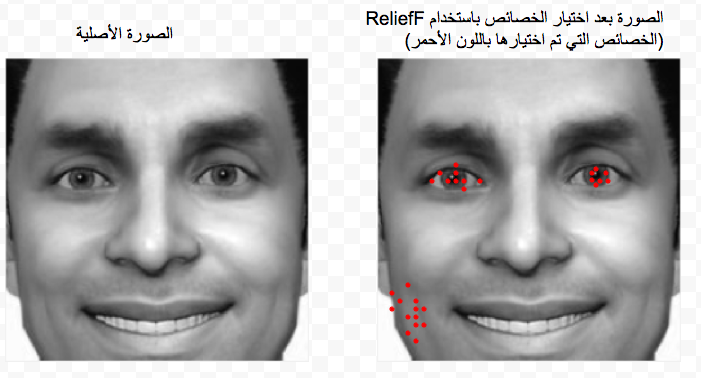
الشكل الأول
انظر الآن لو قمنا بتطبيق إحدى الخوارزميات المشهورة باستخراج الخصائص FE على الصور. دعنا نستخدم Principal Component Analysis PCA.
انظر الشكل الثاني أدناه، لاتجد أي شئ من خصائص الصورة بقي على حاله. ولاتستطيع أن تعرف ماهي الخصائص الأصلية في الصورة القادرة على إعطاءك نتائج أفضل. فلاتستطيع أن تقول أن العينين مثلا هي الخصائص التي أعطتني أفضل النتائج، لأن الصورة في بعد جديد استخدمنا فيه Eigen Space مثلا.
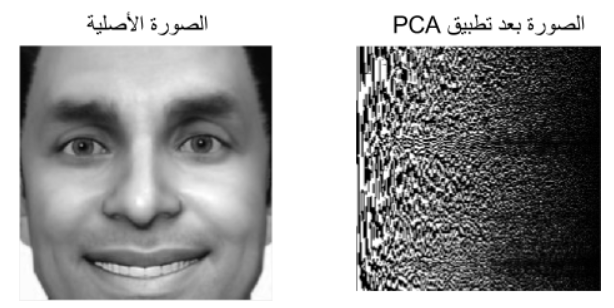
الشكل الثاني
لكن سؤالك عن العشوائية مهم جداً، فهل العشوائية تعطي نتائج جيدة؟ متى؟ الجواب أحياناً. في الحالات التي تكون فيها أبعاد البيانات كبيرة جداً. وهنا تأتي لعنة الأبعاد Curse-of-dimensionality والتي تكون فيها البيانات متشابهه لحد كبير، أو عندما يكون عندي عدد الأبعاد أكبر بكثير من عدد البيانات High dimensionality, low sample size، ومن المعلوم رياضيا أنه في هذه الحالة فإن أي معادلة مستحيلة الحل، وهنا تتدخل الرياضيات بما يسمى ال Optimization. وعندها نقوم بالبحث عن أفضل مجموعة من الخصائص التي ليست بالضرورة تعطي أفضل النتائج على عموم البيانات global بل على جزء محدد منها local حسب نوع المشكلة هل هي Convex أو Noncovex. وهذي يعاني منها كثيراً من يستخدم الذكاء الاصطناعي في المشكلات الطبية لأن عدد البيانات قليل مقارنة بأبعادها أو خصائصها. لأن استخراج البيانات الطبية مكلف نسبيا مقارنة بغيره من البيانات ناهيك عن الخصوصية privacy التي تكون في الملفات الطبية. وهناك حالات أخرى تعطي النتائج العشوائية جودة مناسبة كأن تكون الخصائص ذات العلاقة بمجال الدراسة كثيرة في فضاء الخصائص أو أن تكون الخصائص غير ذات علاقة مباشرة بمجال الدراسة… وغيرها من الحالات.
أرجو أن أكون أجبت على سؤالك.. 🙂